WAL-G for PostgreSQL
You can use wal-g as a tool for making encrypted, compressed PostgreSQL backups (full and incremental) and push/fetch them to/from remote storages without saving it on your filesystem.
Configuration
WAL-G uses the usual PostgreSQL environment variables to configure its connection, especially including PGHOST, PGPORT, PGUSER, and PGPASSWORD/PGPASSFILE/~/.pgpass.
PGHOST can connect over a UNIX socket. This mode is preferred for localhost connections, set PGHOST=/var/run/postgresql to use it. WAL-G will connect over TCP if PGHOST is an IP address.
WALG_DISK_RATE_LIMIT
To configure disk read rate limit during backup-push in bytes per second.
Concurrency values can be configured using:
WALG_DOWNLOAD_CONCURRENCY
To configure how many goroutines to use during backup-fetch and wal-fetch, use WALG_DOWNLOAD_CONCURRENCY. By default, WAL-G uses the minimum of the number of files to extract and 10.
WALG_DOWNLOAD_FILE_RETRIES
To configure how many times failed file will be retried during backup-fetch and wal-fetch, use WALG_DOWNLOAD_FILE_RETRIES. By default is set to 15.
WALG_PREFETCH_DIR
By default WAL prefetch is storing prefetched data in pg_wal directory. This ensures that WAL can be easily moved from prefetch location to actual WAL consumption directory. But it may have negative consequences if you use it with pg_rewind in PostgreSQL 13. PostgreSQL 13 is able to invoke restore_command during pg_rewind. Prefetched WAL can generate false failure of pg_rewind. To avoid it you can either turn off prefetch during rewind (set WALG_DOWNLOAD_CONCURRENCY = 1) or place wal prefetch folder outside PGDATA. For details see this pgsql-hackers thread.
WALG_UPLOAD_CONCURRENCY
To configure how many concurrency streams to use during backup uploading, use WALG_UPLOAD_CONCURRENCY. By default, WAL-G uses 16 streams.
WALG_UPLOAD_DISK_CONCURRENCY
To configure how many concurrency streams are reading disk during backup-push. By default, WAL-G uses 1 stream.
TOTAL_BG_UPLOADED_LIMIT(e.g.1024)
Overrides the default number of WAL files to upload during one scan. By default, at most 32 WAL files will be uploaded.
WALG_SENTINEL_USER_DATA
This setting allows backup automation tools to add extra information to JSON sentinel file during backup-push. This setting can be used e.g. to give user-defined names to backups. Note: UserData must be a valid JSON string.
WALG_PREVENT_WAL_OVERWRITE
If this setting is specified, during wal-push WAL-G will check the existence of WAL before uploading it. If the different file is already archived under the same name, WAL-G will return the non-zero exit code to prevent PostgreSQL from removing WAL.
WALG_DELTA_MAX_STEPS
Delta-backup is the difference between previously taken backup and present state. WALG_DELTA_MAX_STEPS determines how many delta backups can be between full backups. Defaults to 0.
Restoration process will automatically fetch all necessary deltas and base backup and compose valid restored backup (you still need WALs after start of last backup to restore consistent cluster).
Delta computation is based on ModTime of file system and LSN number of pages in datafiles.
WALG_DELTA_ORIGIN
To configure base for next delta backup (only if WALG_DELTA_MAX_STEPS is not exceeded). WALG_DELTA_ORIGIN can be LATEST (chaining increments), LATEST_FULL (for bases where volatile part is compact and chaining has no meaning - deltas overwrite each other). Defaults to LATEST.
WALG_TAR_SIZE_THRESHOLD
To configure the size of one backup bundle (in bytes). Smaller size causes granularity and more optimal, faster recovering. It also increases the number of storage requests, so it can costs you much money. Default size is 1 GB (1 << 30 - 1 bytes).
WALG_TAR_DISABLE_FSYNC
Disable calling fsync after writing files when extracting tar files.
WALG_PG_WAL_SIZE
To configure the wal segment size if different from the postgres default of 16 MB
WALG_UPLOAD_WAL_METADATA
To upload metadata related to wal files. WALG_UPLOAD_WAL_METADATA can be INDIVIDUAL (generates metadata for all the wal logs) or BULK( generates metadata for set of wal files)
Sample metadata file (000000020000000300000071.json)
{
"000000020000000300000071": {
"created_time": "2021-02-23T00:51:14.195209969Z",
"date_fmt": "%Y-%m-%dT%H:%M:%S.%fZ"
}
}
If the parameter value is NOMETADATA or not specified, it will fallback to default setting (no wal metadata generation)
WALG_ALIVE_CHECK_INTERVAL
To control how frequently WAL-G will check if Postgres is alive during the backup-push. If the check fails, backup-push terminates.
Examples:
- 0 - disable the alive checks
- 1m - check every 1 minute (default value)
- 10s - check every 10 seconds
- 10m - check every 10 minutes
WALG_STOP_BACKUP_TIMEOUT
Timeout for the pg_stop_backup() call. By default, there is no timeout.
Examples:
- 0 - disable the timeout (default value)
- 10s - 10 seconds timeout
- 10m - 10 minutes timeout
Usage
backup-fetch
When fetching base backups, the user should pass in the name of the backup and a path to a directory to extract to. If this directory does not exist, WAL-G will create it and any intermediate subdirectories.
wal-g backup-fetch ~/extract/to/here example-backup
WAL-G can also fetch the latest backup using:
wal-g backup-fetch ~/extract/to/here LATEST
WAL-G can fetch the backup that has the specific UserData (stored in backup metadata) using the --target-user-data flag or WALG_FETCH_TARGET_USER_DATA variable:
wal-g backup-fetch /path --target-user-data "{ \"x\": [3], \"y\": 4 }"
Reverse delta unpack
Beta feature: WAL-G can unpack delta backups in reverse order to improve fetch efficiency.
To activate this feature, do one of the following:
- set the
WALG_USE_REVERSE_UNPACKenvironment variable - add the --reverse-unpack flag
wal-g backup-fetch /path LATEST --reverse-unpack
Redundant archives skipping
With reverse delta unpack turned on, you also can turn on redundant archives skipping. Since this feature involves both backup creation and restore process, in order to fully enable it you need to do two things:
-
Optional. Increases the chance of archive skipping, but may result in slower backup creation. Enable rating tar ball composer for
backup-push. -
Enable redundant backup archives skipping during backup-fetch. Do one of the following:
-
set the
WALG_USE_REVERSE_UNPACKandWALG_SKIP_REDUNDANT_TARSenvironment variables - add the
--reverse-unpackand--skip-redundant-tarsflags
wal-g backup-fetch /path LATEST --reverse-unpack --skip-redundant-tars
Partial restore (experimental)
During partial restore wal-g restores only specified databases' files. Use 'database' or 'database/namespace.table' as a parameter ('public' namespace can be omitted).
wal-g backup-fetch /path LATEST --restore-only=my_database,"another database",database/my_table
Note: Double quotes are only needed to insert spaces and will be ignored
Example:
--restore-only=my_db,"another db"
is equivalent to
--restore-only=my_db,another" "db
or even
--restore-only=my_db,anoth"e"r" "d"b"
Require files metadata with database names data, which is automatically collected during local backup. With remote backup this option does not work.
Restores system databases and tables automatically.
Options --skip-redundant-tars and --reverse-unpack are set automatically.
Because of unrestored databases' or tables remains are still in system tables, it is recommended to drop them.
backup-push
When uploading backups to storage, the user should pass the Postgres data directory as an argument.
wal-g backup-push $PGDATA
WAL-G will check that command argument, environment variable PGDATA and config setting PGDATA are the same, if set.
If a backup is started from a standby server, WAL-G will monitor the timeline of the server. If a promotion or timeline change occurs during the backup, the data will be uploaded but not finalized, and WAL-G will exit with an error. The logs will contain the necessary information to finalize the backup, which can then be used if you clearly understand the risks.
backup-push can also be run with the --permanent flag, which will mark the backup as permanent and prevent it from being removed when running delete.
Remote backup
WAL-G backup-push allows for two data streaming options:
- Running directly on the database server as the postgres user, wal-g can read the database files from the filesystem. This option allows for high performance, and extra capabilities, such as partial restore or Delta backups.
For uploading backups to S3 using streaming option 1, the user should pass in the path containing the backup started by Postgres as in:
bash
wal-g backup-push /backup/directory/path
- Alternatively, WAL-G can stream the backup data through the postgres BASE_BACKUP protocol. This allows WAL-G to stream the backup data through the tcp layer, allows to run remote, and allows WAL-G to run as a separate linux user. WAL-G does require a database connection with replication privileges. Do note that the BASE_BACKUP protocol does not allow for multithreaded streaming, and that Delta backup currently is not implemented.
To stream the backup data, leave out the data directory. And to set the hostname of the postgres server, you can use the environment variable PGHOST, or the WAL-G argument --pghost.
```bash # Inline PGHOST=srv1 wal-g backup-push
# Export export PGHOST=srv1 wal-g backup-push
# Use commandline option wal-g backup-push --pghost srv1 ```
The remote backup option can also be used to:
- Run Postgres on multiple hosts (streaming replication), and backup with WAL-G using multihost configuration:
wal-g backup-push --pghost srv1,srv2 - Run Postgres on a windows host and backup with WAL-G on a linux host:
PGHOST=winsrv1 wal-g backup-push - Schedule WAL-G as a Kubernetes CronJob
Rating composer mode
In the rating composer mode, WAL-G places files with similar updates frequencies in the same tarballs during backup creation. This should increase the effectiveness of backup-fetch redundant archives skipping. Be aware that although rating composer allows saving more data, it may result in slower backup creation compared to the default tarball composer.
To activate this feature, do one of the following:
- set the
WALG_USE_RATING_COMPOSERenvironment variable - add the --rating-composer flag
wal-g backup-push /path --rating-composer
Copy composer mode
In the copy composer mode, WAL-G makes a full backup and copies unchanged tar files from previous full backup. In case when there are no previous full backup, regular composer is used.
To activate this feature, do one of the following:
- set the
WALG_USE_COPY_COMPOSERenvironment variable - add the --copy-composer flag
wal-g backup-push /path --copy-composer
Database composer mode
In the database composer mode, WAL-G separated files from different directories inside default tablespace and packs them in different tars. Designed to increase partial restore performance.
To activate this feature, do one of the following:
- set the
WALG_USE_DATABASE_COMPOSERenvironment variable - add the --database-composer flag
wal-g backup-push /path --database-composer
Backup without metadata
By default, WAL-G tracks metadata of the backed up files. If millions of files are backed up (typically in case of hundreds of databases and thousands of tables in each database), tracking this metadata alone would require GBs of memory.
If --without-files-metadata or WALG_WITHOUT_FILES_METADATA is enabled, WAL-G does not track metadata of the files backed up. This significantly reduces the memory usage on instances with > 100k files.
Limitations
- Cannot be used with
rating-composer,copy-composer - Cannot be used with
WALG_DELTA_MAX_STEPSsetting ordelta-from-user-data,delta-from-nameflags.
To activate this feature, do one of the following:
- set the
WALG_WITHOUT_FILES_METADATAenvironment variable - add the
--without-files-metadataflag
wal-g backup-push /path --without-files-metadata
Create delta backup from specific backup
When creating delta backup (WALG_DELTA_MAX_STEPS > 0), WAL-G uses the latest backup as the base by default. This behaviour can be changed via following flags:
-
--delta-from-nameflag orWALG_DELTA_FROM_NAMEenvironment variable to choose the backup with specified name as the base for the delta backup -
--delta-from-user-dataflag orWALG_DELTA_FROM_USER_DATAenvironment variable to choose the backup with specified user data as the base for the delta backup
Examples:
wal-g backup-push /path --delta-from-name base_000000010000000100000072_D_000000010000000100000063
wal-g backup-push /path --delta-from-user-data "{ \"x\": [3], \"y\": 4 }"
When using the above flags in combination with WALG_DELTA_ORIGIN setting, WALG_DELTA_ORIGIN logic applies to the specified backup. For example:
list of backups in storage:
base_000000010000000100000040 # full backup
base_000000010000000100000046_D_000000010000000100000040 # 1st delta
base_000000010000000100000061_D_000000010000000100000046 # 2nd delta
base_000000010000000100000070 # full backup
export WALG_DELTA_ORIGIN=LATEST_FULL
wal-g backup-push /path --delta-from-name base_000000010000000100000046_D_000000010000000100000040
wal-g logs:
INFO: Selecting the backup with name base_000000010000000100000046_D_000000010000000100000040 as the base for the current delta backup...
INFO: Delta will be made from full backup.
INFO: Delta backup from base_000000010000000100000040 with LSN 140000060.
Page checksums verification
To enable verification of the page checksums during the backup-push, use the --verify flag or set the WALG_VERIFY_PAGE_CHECKSUMS env variable. If found any, corrupted block numbers (currently no more than 10 of them) will be recorded to the backup sentinel json, for example:
...
"/base/13690/13535": {
"IsSkipped": true,
"MTime": "2020-08-20T21:02:56.690095409+05:00",
"IsIncremented": false
},
"/base/16384/16397": {
"CorruptBlocks": [
1
],
"IsIncremented": false,
"IsSkipped": false,
"MTime": "2020-08-21T19:09:52.966149937+05:00"
},
...
wal-fetch
When fetching WAL archives from S3, the user should pass in the archive name and the name of the file to download to. This file should not exist as WAL-G will create it for you.
WAL-G will also prefetch WAL files ahead of the asked WAL file. These files will be cached in ./.wal-g/prefetch directory. Cached files older than the recently asked WAL file will be deleted from the cache, to prevent cache bloating. If a cached file is requested with wal-fetch, this will also remove it from the cache, but trigger caching of the new file.
wal-g wal-fetch example-archive new-file-name
This command is intended to be executed from the Postgres restore_command parameter.
Note: wal-fetch will exit with errorcode 74 (EX_IOERR: input/output error, see sysexits.h for more info) if the WAL-file is not available in the repository.
All other errors end in exit code 1, and should stop PostgreSQL rather than ending PostgreSQL recovery.
For PostgreSQL that should be any error code between 126 and 255, which can be achieved with a simple wrapper script.
Please see https://github.com/wal-g/wal-g/pull/1195 for more information.
wal-push
When uploading WAL archives to S3, the user should pass in the absolute path to where the archive is located.
wal-g wal-push /path/to/archive
This command is intended to be executed from the Postgres archive_command parameter.
wal-show
Show information about the WAL storage folder. wal-show shows all WAL segment timelines available in storage, displays the available backups for them, and checks them for missing segments.
- if there are no gaps (missing segments) in the range, final status is
OK - if there are some missing segments found, final status is
LOST_SEGMENTS
wal-g wal-show
By default, wal-show shows available backups for each timeline. To turn it off, add the --without-backups flag.
By default, wal-show output is plaintext table. For detailed JSON output, add the --detailed-json flag.
wal-verify
Run series of checks to ensure that WAL segment storage is healthy. Available checks:
integrity
Ensure that there is a consistent WAL segment history for the cluster so WAL-G can perform a PITR for the backup. Essentially, it checks that all the WAL segments in the range [oldest backup start segment, current cluster segment) are available in storage. If no backups found, [1, current cluster segment) range will be scanned.
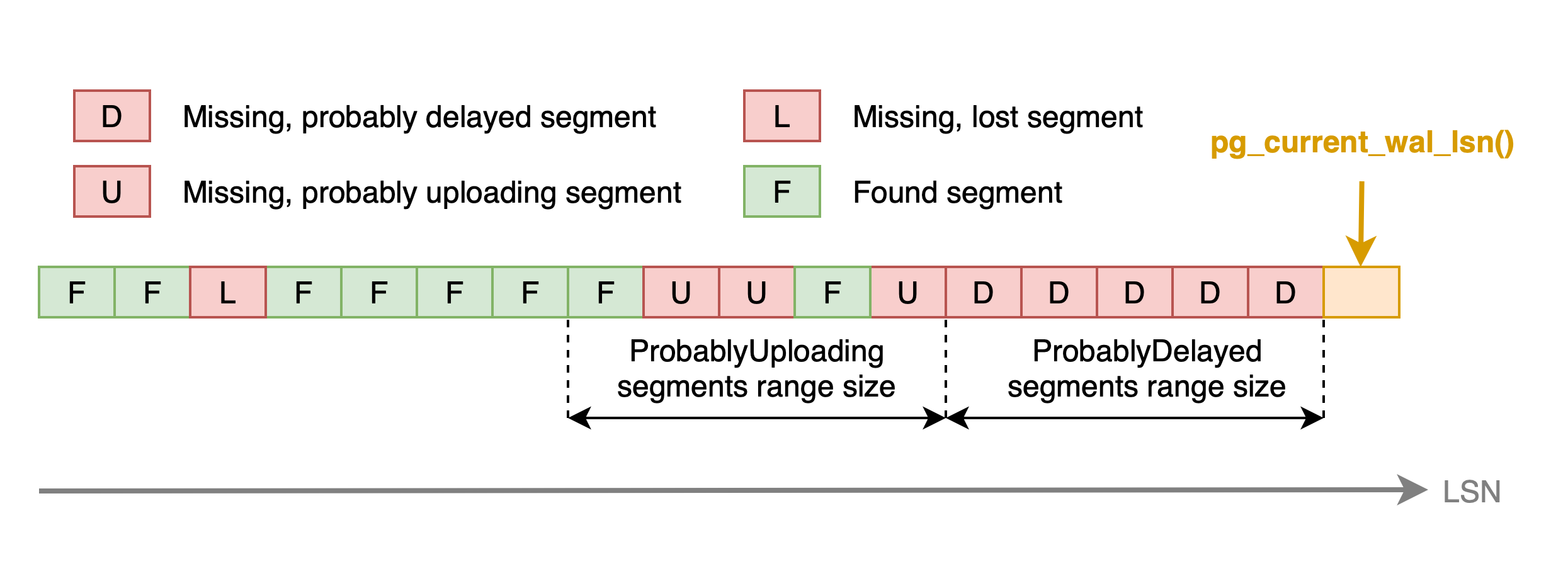
In integrity check output, there are four statuses of WAL segments:
FOUNDsegments are present in WAL storageMISSING_DELAYEDsegments are not present in WAL storage, but probably Postgres did not try to archive them viaarchive_commandyetMISSING_UPLOADINGsegments are the segments which are not present in WAL storage, but looks like that they are in the process of uploading to storageMISSING_LOSTsegments are not present in WAL storage and notMISSING_UPLOADINGnorMISSING_DELAYED
ProbablyUploading segments range size is taken from WALG_UPLOAD_CONCURRENCY setting.
ProbablyDelayed segments range size is controlled via WALG_INTEGRITY_MAX_DELAYED_WALS setting.
Output consists of:
- Status of
integritycheck:OKif there are no missing segmentsWARNINGif there are some missing segments, but they are notMISSING_LOSTFAILUREif there are someMISSING_LOSTsegments
- A list that shows WAL segments in chronological order grouped by timeline and status.
timeline
Check if the current cluster timeline is greater than or equal to any of the storage WAL segments timelines. This check is useful to detect split-brain conflicts. Please note that this check works correctly only if new storage created, or the existing one cleaned when restoring from the backup or performing pg_upgrade.
Output consists of:
- Status of
timelinecheck:OKif current timeline id matches the highest timeline id found in storageWARNINGif could not determine if current timeline matches the highest in storageFAILUREif current timeline id is not equal to the highest timeline id found in storage
- Current timeline id.
- The highest timeline id found in WAL storage folder.
Usage:
wal-g wal-verify [space separated list of checks]
# For example:
wal-g wal-verify integrity timeline # perform integrity and timeline checks
wal-g wal-verify integrity # perform only integrity check
By default, wal-verify output is plaintext. To enable JSON output, add the --json flag.
Example of the plaintext output:
[wal-verify] integrity check status: OK
[wal-verify] integrity check details:
+-----+--------------------------+--------------------------+----------------+--------+
| TLI | START | END | SEGMENTS COUNT | STATUS |
+-----+--------------------------+--------------------------+----------------+--------+
| 3 | 00000003000000030000004D | 0000000300000004000000F0 | 420 | FOUND |
| 4 | 0000000400000004000000F1 | 000000040000000800000034 | 836 | FOUND |
+-----+--------------------------+--------------------------+----------------+--------+
[wal-verify] timeline check status: OK
[wal-verify] timeline check details:
Highest timeline found in storage: 4
Current cluster timeline: 4
Example of the JSON output:
{
"integrity":{
"status":"OK",
"details":[
{
"timeline_id":3,
"start_segment":"00000003000000030000004D",
"end_segment":"0000000300000004000000F0",
"segments_count":420,
"status":"FOUND"
},
{
"timeline_id":4,
"start_segment":"0000000400000004000000F1",
"end_segment":"000000040000000800000034",
"segments_count":836,
"status":"FOUND"
}
]
},
"timeline":{
"status":"OK",
"details":{
"current_timeline_id":4,
"highest_storage_timeline_id":4
}
}
}
wal-receive
Receive WAL stream using PostgreSQL streaming replication and push to the storage.
You can set WALG_SLOTNAME variable to define the replication slot name to be used (defaults to walg). The slot name can only consist of the following characters: [0-9A-Za-z_].
When uploading WAL archives to S3, the user should pass in the absolute path to where the archive is located.
wal-g wal-receive
backup-mark
Backups can be marked as permanent to prevent them from being removed when running delete. Backup permanence can be altered via this command by passing in the name of the backup (retrievable via wal-g backup-list --pretty --detail --json), which will mark the named backup and all previous related backups as permanent. The reverse is also possible by providing the -i flag.
wal-g backup-mark example-backup -i
catchup-push
To create a catchup incremental backup, the user should pass the path to the master Postgres directory and the LSN of the replica for which the backup is created.
Steps: 1) Stop replica 2) Get replica LSN (for example using pg_controldata command) 3) Start uploading incremental backup on master.
wal-g catchup-push /path/to/master/postgres --from-lsn replica_lsn
catchup-fetch
To accept catchup incremental backup created by catchup-push, the user should pass the path to the replica Postgres
directory and name of the backup.
wal-g catchup-fetch /path/to/replica/postgres backup_name
catchup-send and catchup-recieve
These commands are used in conjunction to catchup lagging replica. On a standby you should run catchup-recieve, then on a primary catchup-send. Standby Postgres must be stopped during this procedure.
wal-g catchup-receive ${PGDATA_STANDBY} 1337 &
wal-g catchup-send ${PGDATA_PRIMARY} hostname:1337
copy
This command will help to change the storage and move the set of backups there or write the backups on magnetic tape. For example, wal-g copy --from=config_from.json --to=config_to.json will copy all backups.
Flags:
-b, --backup-name stringCopy specific backup-f, --from stringStorage config from where should copy backup-t, --to stringStorage config to where should copy backup-w, --with-historyIf set - copy WALs older than backup finish_lsn. If not - copy only WALs from start_lsn to finish_lsn
delete garbage
Deletes outdated WAL archives and backups leftover files from storage, e.g. unsuccessfully backups or partially deleted ones. Will remove all non-permanent objects before the earliest non-permanent backup. This command is useful when backups are being deleted by the delete target command.
Usage:
wal-g delete garbage # Deletes outdated WAL archives and leftover backups files from storage
wal-g delete garbage ARCHIVES # Deletes only outdated WAL archives from storage
wal-g delete garbage BACKUPS # Deletes only leftover (partially deleted or unsuccessful) backups files from storage
The garbage target can be used in addition to the other targets, which are common for all storages.
wal-restore
Restores the missing WAL segments that will be needed to perform pg_rewind from storage. The current version supports only local clusters.
Usage:
wal-g wal-restore path/to/target-pgdata path/to/source-pgdata
daemon
Archives and fetch all WAL segments in the background. Works with the PostgreSQL archive library walg_archive or walg-daemon-client.
Usage:
wal-g daemon path/to/socket-descriptor
Configuration:
WALG_DAEMON_WAL_UPLOAD_TIMEOUT
To configure time limit for every WAL archive in daemon. Hanging for a longer time operations will be interrupted. Default value is 60s.
pgBackRest backups support (beta version)
pgbackrest backup-list
List pgbackrest backups.
Usage:
wal-g pgbackrest backup-list [--pretty] [--json] [--detail]
pgbackrest backup-fetch
Fetch pgbackrest backup. For now works only with full backups, incr and diff backups are not supported.
Usage:
wal-g pgbackrest backup-fetch path/to/destination-directory backup-name
pgbackrest wal-fetch
Fetch wal file from pgbackrest backup
Usage:
wal-g pgbackrest wal-fetch example-archive new-file-name
pgbackrest wal-show
Show wal files from pgbackrest backup
Usage:
wal-g pgbackrest wal-show
Failover archive storages (experimental)
It's possible to configure WAL-G for using additional "failover" storages, which are used in case the primary storage becomes unavailable. This might be useful to avoid out-of-disk-space issues.
The following commands support failover storages:
- wal-push
- wal-fetch
- wal-prefetch
- backup-push
- backup-fetch
- backup-list
- delete (including all subcommands)
Configuration
WALG_FAILOVER_STORAGES
A nested section with settings of failover storages with their names. The primary storage settings are taken from the root of the config. The primary storage is always used if alive. If not, the first alive failover storage is used (for most of the commands, but some commands uses all alive storages). The order of failover storages is determined by sorting their names lexicographically.
Please note that to use this feature WAL-G must be configured using a config file, because it's impossible to put this nested structure into an environment variable.
Example:
WALG_FAILOVER_STORAGES:
TEST_STORAGE:
AWS_SECRET_ACCESS_KEY: "S3_STORAGE_KEY_1"
AWS_ACCESS_KEY_ID: "S3_STORAGE_KEY_ID_1"
WALE_S3_PREFIX: "s3://some-s3-storage-1/"
STORAGE2:
AWS_SECRET_ACCESS_KEY: "S3_STORAGE_KEY_2"
AWS_ACCESS_KEY_ID: "S3_STORAGE_KEY_ID_2"
WALE_S3_PREFIX: "s3://some-s3-storage-2/"
FILE_STORAGE:
WALG_FILE_PREFIX: "/some/prefix"
Storage aliveness checking
WAL-G maintains a list of all storage statuses at any given moment, and uses only alive storages during command executions. This list serves as a cache as we don't want to check every single storage on each I/O operation.
This cache is stored in two locations: in memory and in a file. The memory one is shared withing a single WAL-G process, and the file is shared between subsequent WAL-G runs of one or different WAL-G installations.
There are two sources of information that affects storage statuses in the cache: - Explicit checks. These are separate routines executed on storages to check if they are alive for RO / RW workload. - Monitoring actual operations. Each time some operation is performed on a storage, its result is reported and applied to the storage's "aliveness" metrika. This metrika is calculated using the Exponential Moving Average algorithm.
Explicit checks are used only if some storage hasn't been used yet at all or wasn't used for a long time so its status TTL has expired. For example, if a storage got dead and wasn't used by WAL-G commands because of that, its status eventually gets outdated in the cache. In order to return it to the cache the explicit check is performed.
You can find details of configuring the actual operations monitoring in the section below.
WALG_FAILOVER_STORAGES_CHECK(=trueby default)
Allows to disable aliveness checks at all. In this case, all configured storages are used, and all are considered alive.
WALG_FAILOVER_STORAGES_CHECK_TIMEOUT(=30sby default)
Allows to specify a timeout of explicit checks' routines.
WALG_FAILOVER_STORAGES_CHECK_SIZE(=1mbby default)
Allows to specify a file size that is uploaded in the RW explicit check.
WALG_FAILOVER_STORAGES_CACHE_LIFETIME(=15mby default)
This setting controls the cache TTL for each storage status.
Exponential Moving Average configuration
Applying actual operation statuses uses the EMA algorithm. After each operation, the new aliveness metrika is calculated so:
new_aliveness = (reported_value * α) + (prev_aliveness * (1 - α))
Where α is effectively a "sensitivity" of reported_value comparing to the prev_aliveness.
The reported_value is either the operation weight (in case the operation is successful) or 0 (in case it's not).
Different operations have different weights:
- Checking a file for existence: 1000
- Listing files in a folder: 2000
- Reading a file: 1000 * log_10(file_size_in_mb), but not less than 1000.
- Writing a file: 1000 * log_10(file_size_in_mb), but not less than 1000.
- Deleting a file: 500
- Copying a file: 2000
When aliveness of a dead storage reaches "alive limit", the storage becomes alive. When aliveness of an alive storage reaches "dead limit", it becomes dead. Alive limit is greater than dead limit to make it harder to quickly jump between dead and alive states.
In the formula above, α is also not a constant, it changes within some limits, depending on the current aliveness value and the storage status (dead / alive).
α changes linearly within the configured ranges, and ranges are different for alive and dead storages.
- For an alive storage, α is maximal with aliveness = 1.0, and minimal with aliveness = dead limit.
- For a dead storage, α is maximal with aliveness = 0, and minimal with aliveness = alive limit.
This can be configured using the following parameters:
WALG_FAILOVER_STORAGES_CACHE_EMA_ALIVE_LIMIT(=0.99by default)
Alive limit value.
WALG_FAILOVER_STORAGES_CACHE_EMA_DEAD_LIMIT(=0.88by default)
Dead limit value.
WALG_FAILOVER_STORAGES_CACHE_EMA_ALPHA_ALIVE_MAX(=0.05by default)
Max EMA Alpha value for an alive storage.
WALG_FAILOVER_STORAGES_CACHE_EMA_ALPHA_ALIVE_MIN(=0.01by default)
Min EMA Alpha value for an alive storage.
WALG_FAILOVER_STORAGES_CACHE_EMA_ALPHA_DEAD_MAX(=0.5by default)
Max EMA Alpha value for a dead storage.
WALG_FAILOVER_STORAGES_CACHE_EMA_ALPHA_DEAD_MIN(=0.1by default)
Min EMA Alpha value for a dead storage.
Playground
If you prefer to use a Docker image, you can directly test WAL-G with this playground.
Please note, that is a third-party repository, and we are not responsible for it to always work correctly.